前言:数据库调优的PJ,我完成的实验部分内容包括基准测试,和一系列调优过程,因此在此记录一下调优过程,具体实验基准测试数据就不放在这里了,需要的请与我联系。本次测试基于hadoopHA环境基础上,使用mysql+hive对选取的数据集(TPC-H提供的GB级标准测试数据)进行性能测试,按照目前流行的TPC-H测试方法,进行了各种标准案例的测试,并在此基础上,进行了Hive配置参数,进行时间优化。
主要工具: CentOS release 6.4 hadoop-2.5.0 hive-1.2.2 TPC-H_on_Hive tpc-h 配置: 三台虚拟机,其中,两台2GB内存20GB硬盘,一台4GB内存20GB硬盘
tpc-h
TPC-H基准测试包括22个查询(Q1~Q22)随机组成查询流 TPC-H模型的评价指标主要为各个查询的响应时间,即从提交查询到结果返回所需时间。TPC-H基准测试的度量单位:每小时执行的查询数(Qph@size)。其中H表示每小时系统执行复杂查询的平均次数,size表示数据库规模的大小,它能够反映出系统在处理查询时的能力。 TPC-H模型的表结构,8张表(表上有些约束等需要满足,参见TPC-H规范),如下: PART:表示零件的信息 SUPPLIER:表示供货商的信息 PARTSUPP:表示供货商的零件的信息 CUSTOMER:表示消费者的信息 ORDERS:表示订单的信息 LINEITEM:表示订单的信息 NATION:表示国家的信息 REGION:表示地区的信息
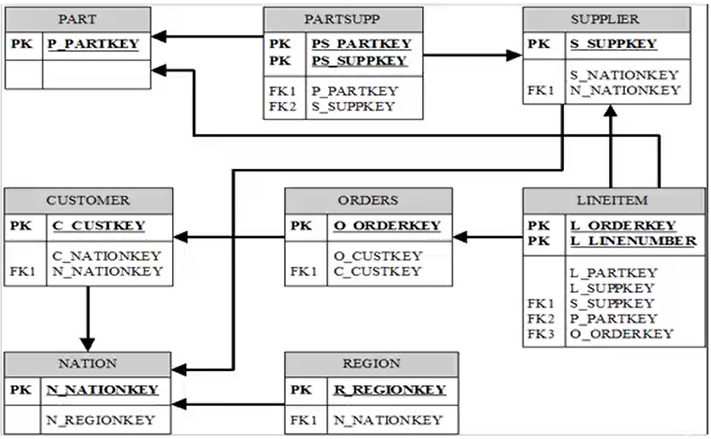 TPC-H表结构图
TPC-H表结构图
调优过程
q4语句:
DROP TABLE orders;
DROP TABLE lineitem;
DROP TABLE q4_order_priority_tmp;
DROP TABLE q4_order_priority;
– create tables and load data
create external table orders (O_ORDERKEY INT, O_CUSTKEY INT, O_ORDERSTATUS STRING, O_TOTALPRICE DOUBLE, O_ORDERDATE STRING, O_ORDERPRIORITY STRING, O_CLERK STRING, O_SHIPPRIORITY INT, O_COMMENT STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘|’ STORED AS TEXTFILE LOCATION ‘/tpch/orders’;
Create external table lineitem (L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT, L_LINENUMBER INT, L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE, L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING, L_SHIPDATE STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING, L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘|’ STORED AS TEXTFILE LOCATION ‘/tpch/lineitem’;
– create the target table
CREATE TABLE q4_order_priority_tmp (O_ORDERKEY INT);
CREATE TABLE q4_order_priority (O_ORDERPRIORITY STRING, ORDER_COUNT INT);
set mapred.min.split.size=536870912;
– the query
INSERT OVERWRITE TABLE q4_order_priority_tmp
select
DISTINCT l_orderkey
from
lineitem
where
l_commitdate < l_receiptdate;
INSERT OVERWRITE TABLE q4_order_priority
select o_orderpriority, count(1) as order_count
from
orders o join q4_order_priority_tmp t
on
o.o_orderkey = t.o_orderkey and o.o_orderdate >= ‘1993-07-01’ and o.o_orderdate < ‘1993-10-01’
group by o_orderpriority
order by o_orderpriority;
我们以q4查询为例,逐步优化,最后总体测试优化结果;
default配置下q4查询总时间为: Time taken:216.158
优化1:部分本地模式
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Let Hive determine whether to run in local mode automatically</description>
</property>
第一项优化我们开启了本地模式,再次运行,得到结果, Time taken:210.367 说明优化产生作用,但是效果并不明显,我们在输出日志注意到如下内容:
Cannot run job locally: Input Size (= 759863287) is larger than hive.exec.mode.local.auto.inputbytes.max (= 134217728)
说明本地模式并不完全,有部分作业超过本地内存输入,因此不在本地进行,因此我们进行第二项优化。
优化2:本地模式完全开启
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>760000000</value>
<description>When hive.exec.mode.local.auto is true, input bytes should less than this for local mode.</description>
</property>
Time taken:67.465 可见优化效果明显。
优化3:开启并行
<property>
<name>hive.exec.parallel</name>
<value>true</value>
</property>
Time taken:76.007 seconds 发现时间并没有缩短反而延长,多次测试后发现不是偶然现象,优化没有效果,查阅资料可能是本地没有足够资源进行并行,加上部分查询本身存在依赖,因此本次优化并没有取得很好的效果,除此之外在完全本地模式下,本地资源已经造成足够大的负担,采用其他优化在此之上时间并没有缩短,因此之后的优化中取消完全本地模式,开启半本地模式,其他任务还是提交到集群中进行处理。
优化4:groupby优化
<property>
<name>hive.groupby.skewindata</name>
<value>true</value>
<description>Whether there is skew in data to optimize group by queries</description>
</property>
totaljob=8 Time taken:200.623 我们发现输出日志内容中,job数目从7增加到8,groupby配置用于控制负载均衡,当数据出现倾斜时,如果该变量设置为true,那么Hive会自动进行负载均衡。
优化5:非严格分区模式
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
<description>
In strict mode, the user must specify at least one static partition
in case the user accidentally overwrites all partitions.
In nonstrict mode all partitions are allowed to be dynamic.
</description>
</property>
hive提供了一个严格模式,可以防止用户执行那些可能产生意想不到的不好的效果的查询。即某些查询在严格 模式下无法执行。通过设置hive.mapred.mode的值为strict,可以禁止3种类型的查询。修改配置之后,发现测试在时间运行上没有优化效果 Time taken:202.823 seconds
优化6:独立的jvm中执行map/reduce
<property>
<name>hive.exec.submitviachild</name>
<value>true</value>
<description/>
</property>
Time taken:185.646 seconds 优化效果较为明显,该项配置修改在非本地模式的任务,在自己的jvm上提交任务,猜测减少了网络IO的时间啊,因此时间效率产生优化
优化7:压缩
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
</property>
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
</property>
顺着优化6的思路,可以继续减少网络IO的时间,因此我们开启压缩,任务数据进行压缩会消耗部分cpu时间,但是发现结果中优化依然有效。 Time taken:167.921 seconds
优化8:基于上述配置开启本地模式
Time taken:131.777 seconds 发现运行时间减少,但是多于仅开启本地模式的时间Time taken:64.826,发现多条优化策略在时间上慢于开启完全本地模式时间。
总结
在数据库调优课程上老师说过,调优无非是时间空间上的转化,牺牲空间换取时间或者牺牲时间效率进行空间优化,基于本次调优的一系列过程,我更深刻的学习到,hadoop本身特征是基于海量数据处理,可以将任务提交到多台处理的机制,那么也就决定了,hadoop生态框架利于扩展和海量数据的处理,那么也就牺牲了时间效率,因此,时间优化效果,本地模式更快的结论与此也相契合,如要注重时间效率可以采用spark等实时基于内存实时计算的大数据并行计算框架,可能基于时间的优化更为明显。