Hadoop是一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
运行环境搭建
首先,这个是需要运行在linux系统中的,所以得安装个linux才行,市面上有很多个linux的版本,如红帽子、Fedra、Ubuntu。选哪种呢,对我这种习惯windows的来说,当然要使用方便的,所以选择了Ubuntu。
安装Ubuntu,这里我就不多说了,在官网上有很多,其实也很简单,一路下一步。当然这里可以安装在Vmware虚拟机上,也可以直接安装在硬盘上。 我个人建议,可以直接安装在硬盘上,与现有windows做个双系统。因为后面还要跑开发环境 eclipse,在虚拟机上会有点吃力。 同时安装在硬盘上后,还可以这样玩,在进入windows后,安装 vmware,然后新建虚拟机后,不要创建硬盘,直接使用硬盘的分区,这样, 就可以在vmware中启动安装在硬盘上的ubuntu了。做到双系统,双启动。
这样好处是,当要开发时,可以直接进ubuntu系统,当只是看看代码,以及后面模拟分布式部署时,就可以用vmware来启动,同时再建上几个虚拟机来进行分布式部署。
操作系统准备好后,就需要一些组件了,hadoop比较简单,只需要ssh和java环境。
1.java环境配置
可以在网上下载一个JDK安装包,如:jdk-6u24-linux-i586.bin安装直接在目录下运行./jdk-6u24-linux-i586.bin即可。
然后配置jdk目录:
先进入安装目录 cd jdk-6u24-…,然后输入 PWD 就可以看到java安装目录,复制下来:

命令行执行:sudo gedit /etc/profile
在打开的文件里,追加:
export JAVA_HOME=/home/administrator/hadoop/jdk1.6.0_27 //这里要写安装目录
export PATH=${JAVA_HOME}/bin:$PATH
执行source /etc/profile 立即生效
验证是否安装完成,那比较容易了,在命令行下运行 java -version ant svn ssh 看是否找不到命令,如果都能找到,说明OK了。
2.使用ssh进行无密码验证登录
进入shell命令,输入如下命令,查看是否已经安装好ssh服务,若没有,则使用如下命令进行安装:
sudo apt-get install ssh openssh-server
使用ssh进行无密码验证登录:
1.创建ssh-key,这里我们采用rsa方式,使用如下命令: ssh-keygen -t rsa -P “”
2.出现一个图形,出现的图形就是密码,不用管它
cat ~/.ssh/id_rsa.pub » authorized_keys(好像是可以省略的)
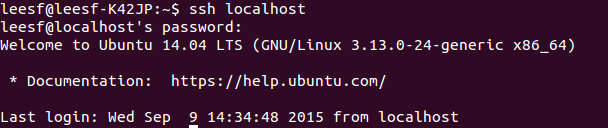
3.然后即可无密码验证登录了,如下:
ssh localhost
成功截图如下:
下载Hadoop安装包
下载Hadoop安装也有两种方式
1.直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.
2.使用shell进行下载,命令如下wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
解压缩Hadoop安装包
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-2.7.1.tar.gz
解压缩完成后出现hadoop2.7.1的文件夹
配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
1.core-site.xml 配置如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/leesf/program/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3.hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/leesf/program/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/leesf/program/hadoop/tmp/dfs/data</value>
</property>
</configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME=”/home/leesf/program/java/jdk1.8.0_60”
启动hadoop
1.初始化HDFS系统
在hadop2.7.1目录下使用如下命令:
bin/hdfs namenode -format
截图如下:
 过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
成功的截图如下:
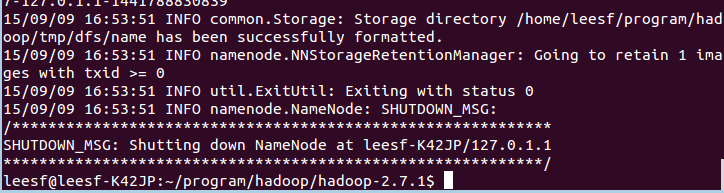
表示已经初始化完成。
2.开启NameNode和DataNode守护进程
使用如下命令开启:
sbin/start-dfs.sh,成功的截图如下:
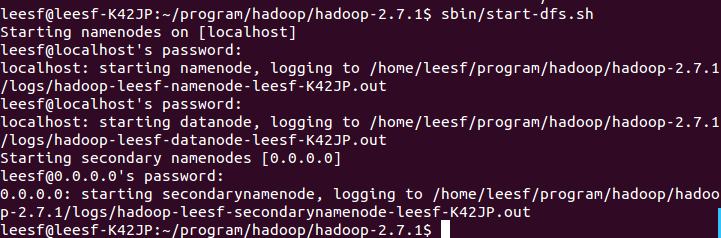
表示数据DataNode和NameNode都已经开启
3.查看进程信息
使用如下命令查看进程信息
jps,截图如下:

4.查看Web UI
在浏览器中输入 http://localhost:50070 ,即可查看相关信息,截图如下:

至此,hadoop的环境就已经搭建好了。