Hadoop
Hadoop是一个用于海量数据统计分析的分布式计算框架,封装了分布式计算中比较困难的进程间通信、负载均衡,任务调度等模块,简单来说,hadoop 就是一个大数据解决方案。它提供了一套分布式系统基础架构, 核心内容包含hdfs和mapreduce。hadoop2.0以后引入yarn。
如图:
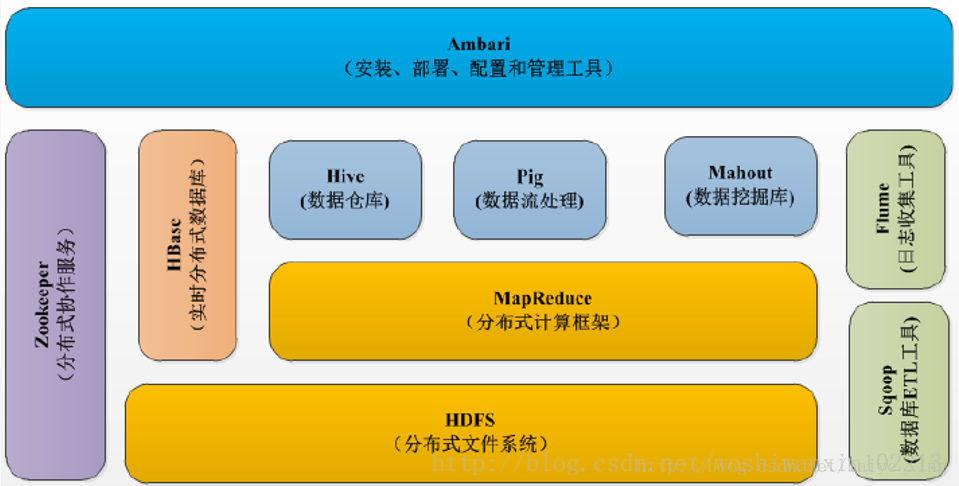
主要模块
- Hadoop Distributed File System(HDFS):分布式文件存储系统。
- MapReduce:并行计算框架(可以自定义计算逻辑的部分)
- Yet Another Resource Negotiator(YARN):另一种资源协调者(顾名思义,Hadoop1.x采用的不是这一个资源管理器)
MapReduce和YARN
- mapreduce是一个分布式运算程序的编程框架,是hadoop数据分析的核心.
- mapreduce的核心思想是将用户编写的逻辑代码和架构中的各个组件整合成一个分布式运算程序,实现一定程序的并行处理海量数据,提高效率.
- 海量数据难以在单机上处理,而一旦将单机版程序扩展到集群上进行分布式运行势必将大大增加程序的复杂程度.引入mapreduce架构,开发人员可以将精力集中于数据处理的核心业务逻辑上,而将分布式程序中的公共功能封装成框架,以降低开发的难度.
- 一个完整的mapreduce程序有三类实例进程
- MRAppMaster:负责整个程序的协调过程
- MapTask:负责map阶段的数据处理
- ReduceTask:负责reduce阶段的数据处理
Hadoop1.x中的MapReduce
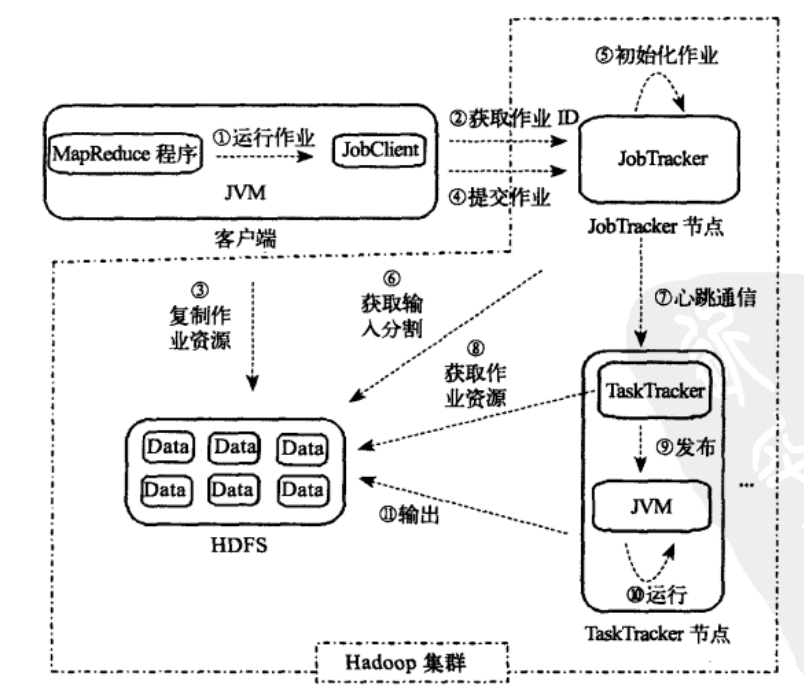 MapReduce在hadoop1.x作业执行的流程图
MapReduce在hadoop1.x作业执行的流程图
在hadoop1.x中,首先客户端要编写好mapreduce程序,然后提交作业也就是job,job的信息会发送到JobTracker上,并为该job分配一个ID值,接下来做检查操作,确认输入目录是否存在,如果不存在,则会抛错,如果存在继续检查输出目录是否存在,如果存在则会抛错,否则继续运行;当检查工作都做好了JobTracker就会配置Job需要的资源了。
其中,
- JobTracker: 主要负责资源监控管理和作业调度 (1)监控所有TaskTracker 与job的健康状况,一旦发现失败,就将相应的任务转移到其他节点; (2)同时JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。
- TaskTracker:是JobTracker与Task之前的桥梁
(1)首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
(2)TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
(3)TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat发送给JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。
Hadoop1.x的MapReduce框架的主要局限:
(1)JobTracker 是 Map-reduce 的集中处理点,存在单点故障,可靠性差;
(2)JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker 失效的风险。
Hadoop2.x中的MapReduce
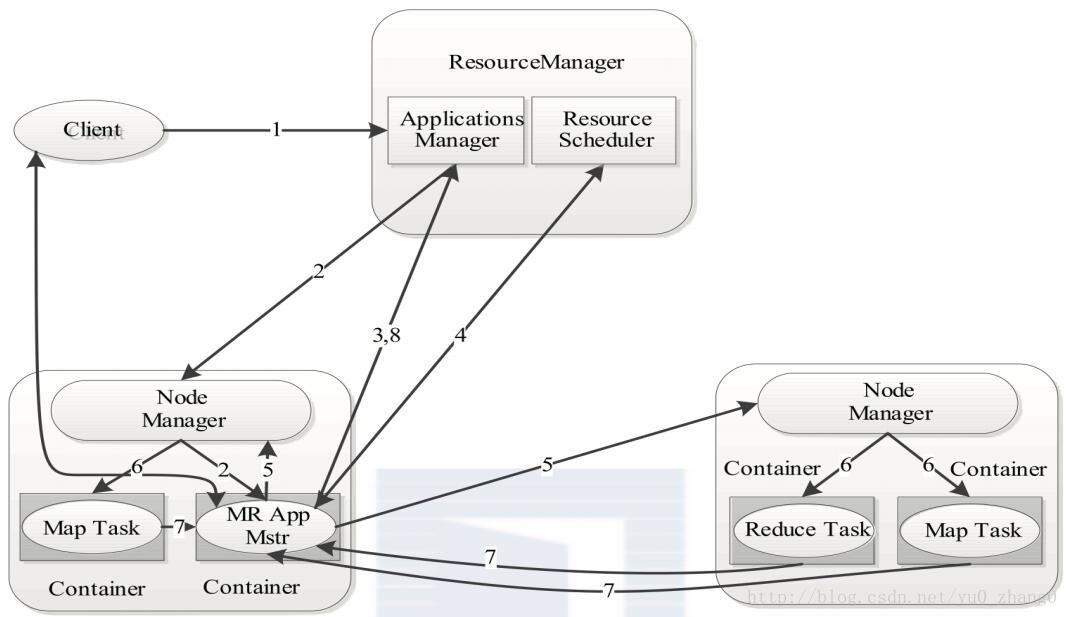 MapReduce在hadoop2.x作业执行的流程图
MapReduce在hadoop2.x作业执行的流程图
两个框架最大的区别在于原来框架中的JobTracker和TaskTracker不见了,取而代之的是ResourceManager、NodeManager和Application Master三个。重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。Resource Manager负责全局资源分配。
YARN总体上仍然是master/slave结构,在整个资源管理框架中,resourcemanager为master,nodemanager是slave。Resourcemanager负责对各个nademanger上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。
ResourceManager是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等;NodeManager是Slave上一个独立运行的进程,负责上报节点的状态;App Master和Container是运行在Slave上的组件,Container是yarn中分配资源的一个单位,包涵内存、CPU等等资源,yarn以Container为单位分配资源。
Client向ResourceManager提交的每一个应用程序都必须有一个Application Master,它经过ResourceManager分配资源后,运行于某一个Slave节点的Container中,具体做事情的Task,同样也运行与某一个Slave节点的Container中。RM,NM,AM乃至普通的Container之间的通信,都是用RPC机制。
Hadoop2.x中的MapReduce优点
(1)新框架将JobTracker的分离,减少了它的资源消耗,使系统更容易从单点故障中恢复,并且监测每个作业子任务状态的程序分布式化了,更安全。
(2)在新框架中,ApplicationMaster是可变的,可以为不同的计算框架编写自己的Application Master,使得更多的计算框架可以运行在Hadoop集群上。
(3)老的框架中,JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在,这个部分就扔给ApplicationMaster做了,而ResourceManager中有一个模块叫ApplicationsManager,它是监测ApplicationMaster的运行状况,如果出问题,会将其在其他机器上重启。
(4)Container很好地起到了资源隔离的作用,让资源更好地被利用起来。