HDFS的主要设计理念
- 1、存储超大文件
这里的“超大文件”是指几百MB、GB甚至TB级别的文件。 - 2、最高效的访问模式是 一次写入、多次读取(流式数据访问)
HDFS存储的数据集作为hadoop的分析对象。在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将设计该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。 - 3、运行在普通廉价的服务器上
HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
HDFS的忌讳
- 1、将HDFS用于对数据访问要求低延迟的场景
由于HDFS是为高数据吞吐量应用而设计的,必然以高延迟为代价。 - 2、存储大量小文件
HDFS中元数据(文件的基本信息)存储在namenode的内存中,而namenode为单点,小文件数量大到一定程度,namenode内存就吃不消了。
HDFS中如何存储(NN、DN及SNN主要功能)
整体架构如图:
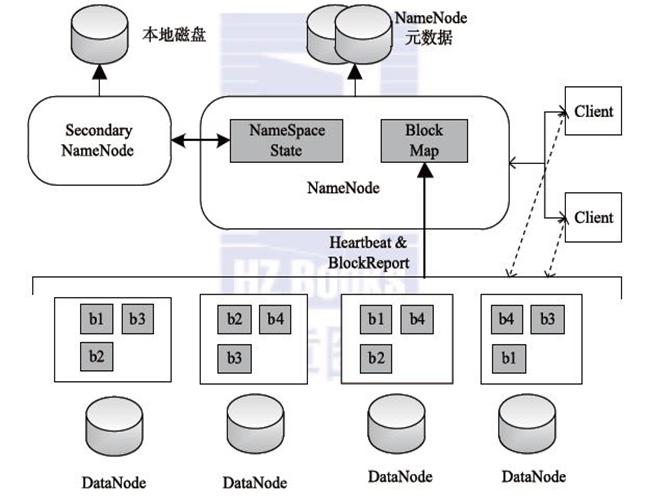
Client
-
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
-
与 NameNode 交互,获取文件的位置信息;与 DataNode 交互,读取或者写入数据。
-
Client提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
NameNode功能
NN是HDFS主从结构中主节点上运行的主要进程,它负责管理从节点DN。NN维护着整个文件系统的文件目录树,文件目录的元信息和文件的数据块索引。这些信息以两种信息保存在本文文件系统中,一种是文件系统镜像(文件名字fsimage),另一种是fsimage的编辑日志(文件名字edits)。 fsimage中保存着某一特定时刻HDFS的目录树、元信息和文件数据块的索引等信息,后续的对这些信息的改动,则保存在编辑日志中,它们一起提供了一个完整的NN的第一关系。通过NN,Client还可以了解到数据块所在的DN的信息。需要注意的是,NN中关于DN的信息是不会保存到NN的本地文件系统的,也就是上面提到的fsimage和edits中。NN每次启动时,都会通过每个DN的上报来动态的建立这些信息。这些信息也就构成了NN第二关系。
综上:
-
1、NameNode主要功能:协调客户端对文件的访问
-
2、NameNode保存metadata(元数据,除了文件内容之外的都是元数据)信息包括:
-
1)文件owership和permissions;文件包含哪些块
-
2)Block保存在哪个DataNode(由DataNode启动时上报)
-
-
3、NameNode的metadate信息在启动后加载到内存:
-
1)metadata存储到磁盘文件名为“fsimages”(命名空间镜像文件,NN主要根据fsimage来进行数据操作)
-
2)edits记录对metadata的操作日志
-
DataNode功能
DN是HDFS中硬盘IO最忙碌的部分:将HDFS的数据块写到Linux本地文件系统中,或者从这些数据块中读取数据。DN作为从节点,会不断的向NN发送心跳。初始化时,每个DN将当前节点的数据块上报给NN。NN也会接收来自NN的指令,比如创建、移动或者删除本地的数据块,并且将本地的更新上报给NN。
-
1、在NameNode的统一调度下进行数据块的创建、存储、删除和复制
-
2、启动DN线程的时候会向NN汇报block信息,之后NN根据汇报的block信息来找到block数据
-
3、通过向NN发送心跳保持与其联系(3秒一次)
SecondaryNameNode功能
首先是NN中的Fsimage和edits文件通过网络拷贝,到达SNN服务器中,拷贝的同时,用户的实时在操作数据,那么NN中就会从新生成一个edits来记录用户的操作,而另一边的SNN将拷贝过来的edits和fsimage进行合并,合并之后就替换NN中的fsimage。之后NN根据fsimage进行操作(当然每隔一段时间就进行替换合并,循环)。当然新的edits与合并之后传输过来的fsimage会在下一次时间内又进行合并。
需要注意的是:
-
1、它不是NN的备份(但可以做备份),它主要工作是帮助NN合并editslog,减少NN启动时间。
-
2、SNN执行合并时机:根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒;根据配置文件设置edits log大小fs.checkpoint.size规定edit文件的最大值默认64MB。
-
3、当删除一个文件的时候其实并不是马上删除,而是在edits log中记录,到一定时间与fsimage通过SNN进行合并的时候进行删除。由于涉及大多的IO和消耗CPU,所以在NN中不做数据操作的合并,而是让另一个机器的CPU去计算实现SNN根据时间来不断合并各个NN,这样用户体验感比较好,速度也是比较快。
-
4、那么通过SNN合并之后的新的FSimage和edits log会被推送到NN中并且替换原来的FSimage和edits log,这样NN 里面隔段时间就是新的数据。
HDFS的读取和写入
如图:
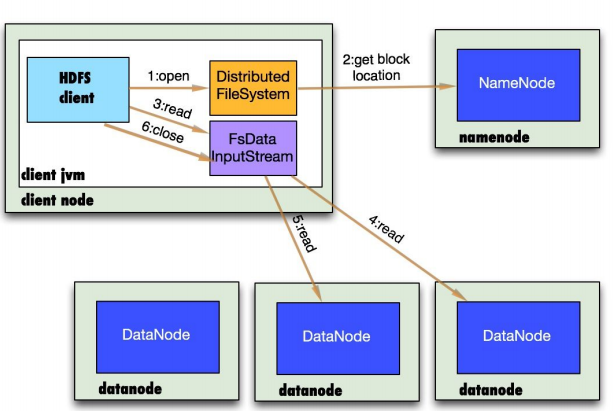
HDFS的文件读取原理,主要包括以下几个步骤:
(1)首先调用FileSystem对象的open方法,事实上是一个DistributedFileSystem的实例。
(2)分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置。
(3)分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法。
(4)DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端。
(5)到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode。
(6)客户端完成读取,对FSDataInputStream调用close()方法关闭连接。
HDFS的文件写入原理,主要包括以下几个步骤:
如图:
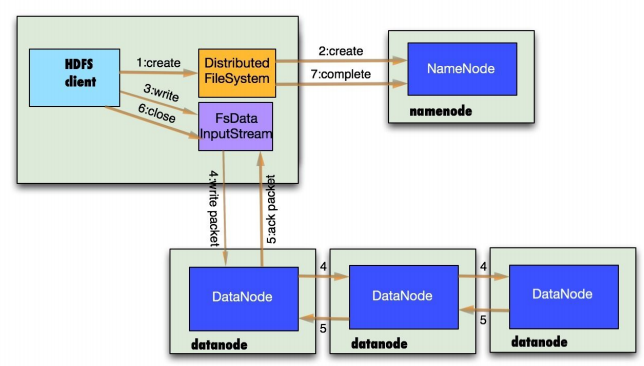
(1)客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
(2)分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件。
(3)Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信,客户端开始写入数据。
(4)FSDataOutputStream将数据分成一个一个的数据包,写入内部队列“数据队列”,DataStreamer负责将数据包依次流式传输到由一组namenode构成的管线中。
(5)DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除。
(6)客户端完成数据的写入,对数据流调用close()方法。
(7)namenode确认完成。